
Motivation: Running Medians
Let’s say you have a rapidly streaming data, you need to keep tracking of the running mean, min and max values. Since sorting a list of values is O(n log(n)),
it is not feasible to continuously calculate these relevant statistics after every update. Instead, we need to have a very efficient way of keeping track
and updating these numbers in real time.
My motivation for writing this post actually came from a different problem; calculating the running median of a continuous stream. When it comes to the mean,
it is straightforward: given the mean M and new value X and the current number of values N, the new mean is simply:
$$ \frac{N*M+X}{N+1} $$
However, when it comes to the median, it is not as straightforward, since we need to know the mid-value of an ordered list! My initial approach for this was to
keep an ordered list that inserts the new value into the right place (found by bisecting recursion) in a continuously growing array, given a list input:
| |
This method DOES give the right answers, but needless to say, it is inefficient, even though the run-time itself is O(n log(n)).
We need to think deeper about it - if all we’re interested in is the running median, there should be no need to keep track of this very cumbersome array that can be
thousands, millions or billions of values!
The change in perspective comes from the fact that this is a very similar problem to keeping track of either min or max of a running list (Do you see how?) If I were asked to keep track of the mininum of streaming values, how would I have approached this problem? Hmm… 🤔
Heaps to the rescue!
A heap is a tree-structure that satisfies the heap property: if you want to have a max heap, the simple restriction is that your parent is larger than you (or equal). In a min heap, the opposite is true.
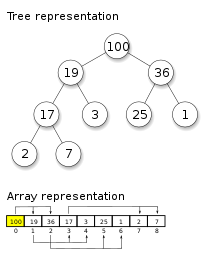
The key property that makes heaps very useful is that inserting a new value or popping the root (either max or min in a max heap or min heap, respectively) is very fast! In case you’re wondering how the insertion and popping operations happen so fast, refer to the first two minutes of this video:
So, let’s take a quick diversion to write a function that keeps track of the running min values using a min heap; in python, this can be done using heapq.
Note that in python, the root element is referred by the 0-element:
| |
That’s great, but how is this problem relevent for the original problem of getting a running median? The trick is to combine a min heap and max heap; keep the smaller half of the elements in a max heap and the larger half of the elements in a min heap. As long as we are careful to keep the size of each heap equal (or the max heap has one more element than min heap if we have an odd number of elements), now getting the median value is just either taking the max element of the min heap (if there are odd number of elements) or the average of the two roots (if there are even number of elements)!
| |
As you can see, each iteration involves two steps - picking which heap to insert the new value, and if needed, re-balance the number of elements in each heap. This is a much faster solution. How much faster are we talking? I ran both methods 500 times using a random list of 1000 elements (Python 3.9.17), and the first method ran in
~4.7 ms while the second method ran in ~720 μs! That is almost a 7-fold decrease, and we have a clear winner here.

Other useful heapq functions
| |
heapq also provides other helpful functions, such as converting a regular array into a heap, merging two heaps, and obtaining the n-th largest or smallest values in an array (How would you implement this yourself? Hint is that it is very similar to the running median problem that we just solved.)
Real-life application: Priority queues
Another very useful real-life scenario that uses heaps is a queueing system which should respect priorities associated with each task, not simply working as a FIFO queue(First-In-First-Out). One example would be theEmergency Room, where patients with more severe conditions need to be treated with a higher priority. A very efficient implementation of such a queueing system can be written like this (example taken directly from python documentation page for heapq: https://docs.python.org/3/library/heapq.html ):
| |
In this example, there are two data structures that keep track of the tasks: a priority queue (heap) pq, and a dictionary entry_finder. Keeping both data structures allows us to not only add and pop the highest priority tasks, but also to remove a specific task that is not necessarily at the root of the heap, with the remove_task() function.
Summary
In this post, we took a deep dive into a very specific data structure - heaps. Heaps are highly efficient for managing priorities, with their ability to provide fast access to the ‘highest’ or ’lowest’ value making them particularly useful in numerous real-life applications. Knowing what kinds of tasks heaps are good for, and also recognizing where they are being used, can be a very helpful tool in your DSA arsenal.